Zu Bild KI habe ich schon einmal etwas geschrieben. Sucht einfach unter „Einführung in die Bild-KI“ mit der Suchfunktion. Ab hier in loser Folge der eine oder andere Workflow. Als Arbeitsumgebung empfehle ich Comfy. Ist problemlos installierbar und zeigt auch recht anschaulich, wie das Ganze funktioniert. Ich beginne mit dem Basis-Workflow. Und der sieht so aus:
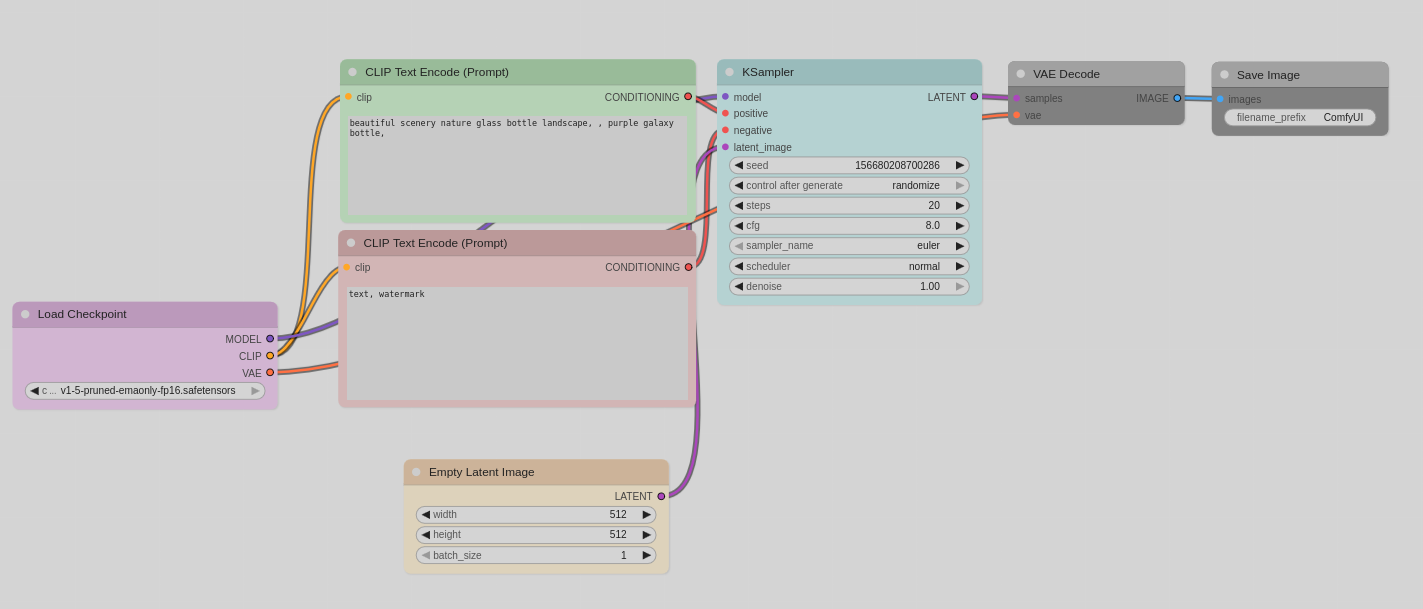
„LoadCheckpoint“ lädt das Modell, mit dem gearbeitet werden soll. Wie man sieht, besteht es aus drei Komponenten: dem eigentlichen Bildmodell (MODEL), dem Textinterpreter (CLIP) und dem VAE-Decoder. Bei manchen Modellen kommen die Komponenten auch getrennt voneinander und man muss sie einzeln laden.
Der Textencoder kümmert sich zunächst um positive und negative Spezifikationen, was man eigentlich möchte. CLIP vom Loader wird mit den entsprechenden Eingängen an den Textknoten verbunden. Da alles farblich kodiert ist, sind Fehler ausgeschlossen. Die Texte (in der Regel Englisch) werden vom Textencoder in interne Maschinenanweisungen übersetzt und an den Sampler weitergeleitet.
An den Sampler werden zusätzlich das Modell und ein leeres Bild angeschlossen. Die Modelle werden zwar mit Text/Bildpaaren trainiert, aber dass genau die Beschreibung, die man eingibt, in den Trainingsdaten ist, ist relativ unwahrscheinlich. Der Sampler sucht nun Bildteile, die statistisch in der Nähe der Textteile sind, und komponiert daraus das seiner Ansicht nach wahrscheinlichste Bild, das der Auftraggeber wünscht. Die Komposition wird in Schritten (STEPS) verfeinert – je mehr Schritte, desto detailreicher das Bild. Zusätzlich wird noch etwas Rauschen hinzu gefügt (SEED), was dafür sorgt, dass mit dem gleichen Text und anderem SEED ein etwas anderes Bild entsteht. Falls der erste Versuch misslingt, kann der Aufraggeber weitere Versuche starten, ohne etwas ändern zu müssen.
Das Ergebnis wird dann mit dem VAE-Decoder von der maschineninternen Darstellung in ein für den Menschen erkennbares Bildtransformiert. Diese Kodierung ist exakt, d.h. man kann ein Bild kodieren und wieder dekodieren und erhält das gleiche Bild zurück.
Da die Texte nicht exakt den Trainingsdaten entsprechen, liefert der Sampler ein Bild, dass nach den Regeln der Wahrscheinlichkeitsrechnung dem Wunsch am Besten entspricht. Das muss natürlich nicht stimmen. Der Auftraggeber kann in diesem Fall seinen Auftragstext anpassen und versuchen, das besser zu beschreiben, was er haben möchte. Das Modell könnte trotzdem auf die Idee kommen, eine Person mit 3 Armen und 4 Beinen sei erwünscht. Dass das nicht so ist, kann man im negativen Prompt mitteilen, also „3 arme, 4 beine“, und das Modell vermeidet das. Iterativ nähert man sich so dem gewünschten Bild.
Das muss nicht immer glücken. Wenn die Wünsche zu weit von den Trainingsdaten entfernt sind, ist das Modell überfordert. Wenn man ein Bild wünscht, in dem Gozilla einen Wolkenkratzer niedertrampelt, in den Trainingsdaten Gozilla aber gar nicht auftaucht, kann das Modell das nicht. Man bekommt irgendwas, aber vermutlich Schwachsinn. Auch wenn Tante Frieda einen Tanz aufführen soll, geht das nur, wenn das Modell Tante Frieda aus den Trainingsdaten kennt.
Das Einfachste ist natürlich, das Modell zu wechseln und eines zu suchen, dass für die eigenen Bedürfnisse besser trainiert ist. Es gibt aber noch einige andere Tricks, die wir in weiteren Beiträgen anschauen werden. Die Workflows sind natürlich etwas komplexer, weshalb ein Einstieg an dieser Stelle erfolgen sollte, möchte man alles wirklich verstehen.